Learn Go
本文是 Golang 的基础学习笔记,大多是对 A Tour of Go 的翻译总结,并参考了 The Go Programming Language 的部分内容自行实现了相关代码并对知识点进行了梳理。
写作环境:
go version go1.17 windows/amd64
命令行操作
Golang 提供了完整的操作命令,用于管理和操作项目。配置好 Golang 环境后,可以直接输入 go 命令查看 Golang 提供的所有命令:
| command | info |
|---|---|
| bug | start a bug report |
| build | compile packages and dependencies |
| clean | remove object files and cached files |
| doc | show documentation for package or symbol |
| env | print Go environment information |
| fix | update packages to use new APIs |
| fmt | gofmt (reformat) package sources |
| generate | generate Go files by processing source |
| get | add dependencies to current module and install them |
| install | compile and install packages and dependencies |
| list | list packages or modules |
| mod | module maintenance |
| run | compile and run Go program |
| test | test packages |
| tool | run specified go tool |
| version | print Go version |
| vet | report likely mistakes in packages |
使用 go help <command> 查询某个命令的详细信息:
go help build
usage: go build [-o output] [build flags] [packages]
...
命令详解
只对常用命令的简单用法进行介绍,详细使用方法需要参照命令行提示信息。
build
该命令用于编译包和依赖,如果是使用了 Go Modules 的项目,编译时会自动根据 go.mod 文件获取依赖包,再进行编译。
普通编译
编译整个目录:
go build
指定输出的文件名:
go build -o hello.exe
指定入口编译:
go build main.go
交叉编译
Golang 支持在很多环境下编译运行,使用go tool dist list命令可以查看 Golang 支持的平台:
go tool dist list
aix/ppc64
android/386
android/amd64
android/arm
android/arm64
darwin/amd64
...
很多时候需要跨系统环境编译,比如在 Windows 下开发可能需要编译 Linux 可以使用的可执行版本,这时候就需要交叉编译:
Windows 下编译
Windows 下需要使用批处理命令,新建一个build.bat文件,填入编译命令执行即可。
# MacOS SET CGO_ENABLED=0 SET GOOS=darwin SET GOARCH=amd64 go build main.go # Linux SET CGO_ENABLED=0 SET GOOS=linux SET GOARCH=amd64 go build main.goLinux 下编译
# MacOS CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go build main.go # Windows CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build main.goMacOS 下编译
# Linux CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build main.go # Windows CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build main.go
参数说明
- CGO_ENABLED:该参数默认为 1,即默认开启 CGO,允许在 Golang 中调用 C 代码,开启之后编译时部分包会使用 C 的实现,因而存在外部依赖(动态链接)。当该参数设置为 0,即禁用 CGO 后,编译时就不会使用 C 实现,从而编译出纯静态的可执行文件
- GOOS:即目标平台
- GOARCH:即目标平台的体系架构
clean
从包源码目录中移除对象文件,例如编译生成的二进制文件以及由其他工具生成的各种文件和目录。
doc
利用格式化的注释生成文档。
env
查询 golang 的环境变量配置。
fix
将包中使用的 API 更新为新版本用法,与 go tool fix 等同。
fmt
格式化源码风格,是对gofmt工具进行的封装,与 gofmt -l -w 等同。
generate
根据代码中的格式化注释来在执行编译过程。
注释格式如下:
//go:generate command argument...
使用go generate命令时会自动执行上述注释中的代码。
get
该命令用于动态获取远程代码包及其所有依赖包,并进行编译安装。默认会将其下载到 GOPATH 下的 src 目录。
install
该命令与go build类似,区别是go install会将编译后的可执行文件放到指定的目录(即$GOBIN文件夹),当$GOBIN环境变量未设置时执行go install会报错。
list
该命令用于列出包名和模块名。
mod
该命令用于管理 Golang 的包,自 Go1.11 开始启用,实现 Modules 管理。将环境变量 $GO111MODULE 设置为 on 或 auto 打开(未来会删除,默认启用 Go Modules)。
常用操作
go mod init [package name]:初始化 Go Modules 项目go mod download [modules name]:下载指定的模块go mod tidy:自动添加缺失的模块并移除未使用的模块
run
编译并运行 Golang 程序。
用法:
go run [build flags] [-exec xprog] package [arguments...]
test
进行单元测试和性能测试。
tool
运行 Golang 提供的工具。
version
查询 Golang 版本。
vet
用于报告包中可能存在的错误,分析当前包中的代码是否正确,等同于go tool vet。
语言基础
命名
Go 语言中的函数名、变量名、常量名、类型名、语句标号和包名等所有的命名,都遵循一个简单的命名规则:一个名字必须以一个字母(Unicode 字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。大写字母和小写字母是不同的:heapSort 和 Heapsort 是两个不同的名字。
Go 的全部关键字如下:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
以上所有关键字都不能用来命名。
Go 的内建常量、内建类型、内建函数如下:
// 内建常量:
true false iota nil
// 内建类型:
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
// 内建函数:
make len cap new append copy close delete
complex real imag
panic recover
上面的这些内建常量、类型和函数名可以被用来命名其他东西,但是在某些时候会出现冲突(同一作用域下)。
Go 的命名习惯为驼峰式命名。例如 quickSort、SetName 等。
包
每一个 Go 程序都是由包(package)组成的,程序从main包开始运行。
根据惯例,包名通常是导入路径的最后一段,例如math/rand包中的每个 go 文件都是以rand为包名。
每个 go 文件的开头都必须指定所属的包,例如package main,指定其属于main包:
package main
在包声明之后,需要导入当前 go 程序所使用的其他包:
import "fmt" // 导入fmt包
当引入了多个包时,需要全部导入:
import "fmt"
import "sync"
通常会将这些包分组导入:
import (
"fmt"
"sync"
)
可以给导入的包一个别名,操作包变量及包函数时可以使用别名:
import f "fmt"
func main() {
f.Println("Hello World")
}
使用.导入包可以省略包名调用包内实体:
import . "math"
func main() {
x := Sqrt(6) // 原为 math.Sqrt()
fmt.Println(x)
}
当导入包却不使用时,可以用_作为包的别名(当只需要调用包的init函数和包级变量时会这么做,后面会讲到):
import _ "fmt"
如果常规导入包却没有显式使用,编译器会报错,无法通过编译。
Golang 区分大小写,并使用大小写区分导出变量(常量、函数、接口等)和私有变量(常量、函数、接口等),类似于 Java 中的 public 和 private。首字母大写的数据类型可以被其他包访问和调用(Public),而首字母小写只能在包内使用(Private)。
package main
import (
"fmt"
"math"
)
func main() {
fmt.Println(math.pi) // 导出名首字母大写,因此这段代码会报错,将pi改为Pi即可
}
程序入口
Golang 程序中 main 包的 main 函数作为其入口,在执行 main 函数之前会先执行 init 函数:
package main
var a int
func init() {
a = 23
}
func main() {
fmt.Println(a) // 23
}
因此在实际编程时常常在 init 函数内进行一些初始化操作,例如读取配置文件等。
基础数据类型
Golang 中包含多种数据类型,并提供了确定的类型长度,方便在不同系统环境下的移植:
bool // 布尔值
string // 字符串
int int8 int16 int32 int64 // 有符号整数
uint uint8 uint16 uint32 uint64 uintptr // 无符号整数
byte // uint8 的别名
rune // int32 的别名,代表一个 Unicode 码点
float32 float64 // 浮点数
complex64 complex128 // 复数
其中,int、uint、uintptr 类型的大小会随位宽的不同而不同,比如在 32 位环境下,它们都占 32bit,而在 64 位环境下它们会占 64bit。
自定义类型
Golang 支持自定义类型,使用 type 关键字指定,并要求指定其底层类型:
type MyTypeA int
type MyTypeB string
变量
变量(Varrible)是编程语言中最基本的量,基本的变量操作有”声明“、”定义“、”初始化“和”赋值“四种。
- 声明(declare):告诉编译器/解析器这个变量的存在,但不分配内存空间
- 定义(defined):为变量分配内存空间,在某些语言(如 C)中声明就包含了定义的过程
- 初始化(initialize):定义变量后,系统并不知道要为该变量分配多少内存空间,通常是使用默认的大小,初始化过程就对变量进行了内存空间的确定
- 赋值(assign):在变量分配内存空间后,对变量的值进行修改
声明
在 Golang 中,变量的声明就包含了定义和初始化的过程,需要指定变量类型:
var a int
fmt.Println(a) // 0
var b, c int // 同时声明多个同类型变量
fmt.Println(b) // 0
fmt.Println(c) // 0
var d bool
fmt.Println(d) // false
变量声明时会根据类型自动初始化,默认是二进制的零值,因此int类型的初始值是0,bool类型的初始值是false,string类型的初始值是""。
存在声明但未使用的变量会导致编译错误:
package main
func main() {
var a int
}
xxx\main.go:4:6: a declared but not used
赋值
使用=来对变量进行赋值:
var a int
a = 12
使用元组赋值可以对多个变量进行赋值:
var a, b int
a, b = 1, 2
// a = 1
// b = 2
利用元组赋值可以进行变量值的交换:
var a, b int
a, b = 1, 2
a, b = b, a
// a = 2
// b = 1
初始化
可以在变量声明时手动初始化:
var a int = 10
fmt.Println(a) // 10
对多个变量初始化:
var a, b int = 1, 2
fmt.Println(a) // 1
fmt.Println(b) // 2
声明存在右值(赋值符号右边的值)时,可以省略变量的类型:
var a = 10
var b, c = 20, 30
fmt.Println(a) // 10
fmt.Println(b) // 20
fmt.Println(c) // 30
和 import 一样,可以分组声明和初始化变量:
var (
a int = 1 // 1
b int // 0
c bool // false
)
短变量声明
在函数内部,可以使用短变量声明,变量类型由右值自动推导:
func main() {
var a uint = 1
b := 3
fmt.Println(a) // 1
fmt.Println(b) // 3
fmt.Println(reflect.TypeOf(a)) // uint
fmt.Println(reflect.TypeOf(b)) // int
}
匿名变量
使用匿名变量来忽略某个值:
func main() {
result, _ := add(10, 20) // 忽略add()返回的第二个值
fmt.Println("Result=", result)
}
func add(a int, b int) (int, string) {
return a + b, "Golang" // 函数add返回了两个值
}
常量
声明
常量(Constant)的声明类似于变量,但使用const关键字,常量只可以是字符、字符串、布尔值和数值型,必须是编译期就确定的值。
常量是固定的值,在程序的整个运行过程中不会改变,变量一般存储与内存中的堆或栈中,位于数据段;而常量通常放在代码段,直接存储其数值,类型由编译器维护。
const pi float64 = 3.1415926
fmt.Println(pi) // 3.1415926
常量可以不指定类型:
const a = 11
和变量一样,常量也支持分组:
const (
a = 11
b = 22
)
当声明多个常量时,如果不指定值,则下面的常量值和其上一行的变量值相等:
const (
a1 = 100 // 100
a2 // 100
a3 // 100
)
和变量不同,常量声明后不是必须要被使用。
数值型常量
数值型常量能提供很高精度的值存储。
一个无类型的常量会根据环境来决定它的类型:
const (
Big = 1 << 100 // 1267650600228229401496703205376
Small = Big >> 99 // 2
)
func needInt(x int) int {
return x*10 + 1
}
func needFloat(x float64) float64 {
return x * 0.1
}
func main() {
fmt.Println(needInt(Small)) // 21
fmt.Println(needInt(Big)) // Overflow
fmt.Println(needFloat(Small)) // 0.2
fmt.Println(needFloat(Big)) // 1.2676506002282295e+29
}
上面的代码声明了一个大数值常量和一个小数值常量,而fmt.Println(needInt(Big))这一段代码在编译期就出现了报错,这是因为这个数值太大超出了int类型能存储的最大长度。从这点可以看出无类型常量的值是可以达到很高的精度的。
iota
iota 可以用作常量的计数器,只能用于常量:
const (
a = iota // 0
b // 1
c // 2
)
可以使用_跳过某些值:
const (
a = iota // 0
_
c // 2
)
由于未初始化常量值会和上一行的值相等,因此会出现以下情况:
const (
a1 = iota // 0
a2 = 100 // 100
a3 // 100
a4 // 100
)
可以中间插入iota计数,但并不是重新计数:
const (
a1 = iota // 0
a2 = 100 // 100
a3 = iota // 2
a4 // 3
)
可以将多个iota定义在同一行:
const (
a1, a2 = iota, iota + 1 // 0, 1
b1, b2 // 1, 2
c1, c2 // 2, 3
)
一个简单的使用iota的例子,其中<<是二进制左移运算符:
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
类型转换
在 Golang 中,所有类型的转换必须是显示转换,否则会编译错误:
i := 42 // int
f := float64(i) // float64
u := uint(f) // uint
var i = 42
var f float64 = i
// cannot use i (type int) as type float64 in assignment
类型推断
有时候会需要知道某个变量的数据类型,这时候就需要类型推断:
func main() {
v := 42
fmt.Printf("%T\n", v) // int
}
通过反射也可以得到变量的类型:
func main() {
v := 42
fmt.Println(reflect.TypeOf(v)) // int
}
函数
函数(Function)是对一段代码的封装,它需要零个或多个输入参数,并会返回零个或多个值。
参数
package main
import "fmt"
func add(x int, y int) int {
return x + y
}
func main() {
fmt.Println(add(42, 13))
}
其中x和y被称为形式参数(形参),因为它们在函数定义时并没有实际的值,只是提供给函数调用的变量名。42和13被称为实际参数(实参),函数接收的实际数值是实参的值。
对于相同类型的形参可以进行省略:
func add(x, y int, c string) string {
return string(rune(x+y)) + c
}
返回值
Golang 还支持函数支持多返回值:
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("hello", "world")
fmt.Println(a, b) // world hello
}
命名返回值
Golang 甚至支持对返回值进行命名:
func split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
return
}
func main() {
fmt.Println(split(17))
}
然而这种函数返回的方式(Naked return statements)会使函数丧失一定的可读性,因此在长函数中不建议使用。
流控制语句
判断(if)
最简单的if语句包含一个条件表达式,当表达式的值为true时,才会执行if判断体的代码段:
if true {
fmt.Println("TRUE")
}
// TRUE
和某些语言不同的是,Golang 只允许判断语句的值为布尔值,不能使用其他数值直接判断。
Golang 支持在if语句中包含短变量声明语句:
if err := function(); err != nil { // 函数function返回错误,nil为空值
fmt.Println("ERROR")
}
if语句通常和else语句一起使用:
var judge = false
if judge {
fmt.Println("TRUE")
} else {
fmt.Println("FALSE")
}
// FALSE
可以使用else if语句进行多次判断,但当一个条件满足时就不会再判断下面的语句:
var num = 55
if num > 12 {
fmt.Println(">12")
} else if num > 16 {
fmt.Println(">16")
} else {
fmt.Println("<=12")
}
// >12
其中else if num > 16永远不会执行到,被称作死代码(Dead Code)。
循环(for)
Golang 中只提供了for循环语句,很多其他语言都提供了如while、do...while循环语句。
for循环语句除循环体以外有三个组成部分,由,分割:
- 初始化语句:在第一次循环前执行
- 条件表达式:在每次循环前判断
- 回报语句:在每次循环后执行
for i := 0; i < 10; i++ {
fmt.Println(i)
}
其中,初始化语句和回报语句是可以省略的:
i := 0
for i < 10 {
fmt.Println("Hi")
i++
}
上面这段循环就变成了其他语言中的while,甚至还能省略循环条件:
for {
fmt.Println("Hi")
}
这段循环就变成了无限循环,等同于while(true)。
continue
可以使用continue语句跳过本次循环:
for i := 0; i < 10; i++ {
if i <= 5 {
continue
}
fmt.Print(i) // 6789
}
break
可以使用break语句结束整个循环:
for i := 0; i < 10; i++ {
if i == 5 {
break
}
fmt.Print(i) // 01234
}
选择(switch)
Switch语句可以用来替代if-else语句,它会按顺序判断条件表达式的值与每一个case是否匹配,匹配则运行当前case:
func main() {
fmt.Print("Go runs on ")
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
fmt.Printf("%s.\n", os)
}
}
// Go runs on windows
上面这段代码使用了runtime包来获取当前运行环境的系统类型,和if语句一样,switch语句也支持短变量声明。
然而switch匹配到一个case后,就不再判断下面的case了,直接会结束整个switch语句,可以使用fallthrough关键字不判断直接执行下一个case:
switch s := 12; { // 注意省略判断语句但保留短变量声明时必须要带上这里的";"
case s <= 10:
fmt.Println("<=10")
case s == 12:
fmt.Println("==12")
fallthrough
default:
fmt.Println("<100")
}
// ==12
// <100
fallthrough只会直接执行其后一条case,并不会执行后面所有的语句,并且fallthrough不能存在于最后一条case(或default)中,否则会报错。
推迟(defer)
defer的详细介绍和注意事项可以参考Go Learning: defer这篇文章。
func main() {
defer fmt.Println("world")
fmt.Println("hello")
}
// hello
// world
其他数据类型
指针
指针(Pointer)是一种特殊的数据类型,它保存的值是一个内存地址,它的零值是nil:
var p *int // <nil>
使用&操作符来生成一个指向操作数的指针,使用*获得指针所指向的值:
i := 10
p := &i
fmt.Println(p) // 0xc000016088
fmt.Println(*p) // 10
可以对指针所指向的值进行修改,但指针变量本身不能进行运算:
i := 10
p := &i
fmt.Println(*p) // 10
*p = 20
fmt.Println(*p) // 20
fmt.Println(i) // 20
结构体
结构体(Struct)是一些字段的集合,可以使用结构体定义变量:
type Person struct {
name string
age uint8
}
func main() {
ps := Person {"Tom", 12}
fmt.Println(ps) // {Tom 12}
}
使用.操作符来操作结构体的字段:
type Person struct {
name string
age uint8
}
func main() {
ps := Person {"Tom", 12}
ps.age = 100
fmt.Println(ps) // {Tom 100}
}
结构体名首字母大写时为可导出,否则不可导出。
结构体指针
type Person struct {
name string
age uint8
}
func main() {
ps := Person {"Tom", 12}
p := &ps
p.name = "Jack" // 等同于(*p).name = "Jack"
fmt.Println(ps)
}
结构体字面量
type Person struct {
name string
age int
}
var (
p1 = Person{"Jack", 12}
p2 = Person{name: "Tom"}
p3 = Person{}
p = &Person{"Cecelia", 16}
)
func main() {
fmt.Println(p1, p2, p3) // {Jack 12} {Tom 0} { 0}
fmt.Println(p) // &{Cecelia 16}
}
结构体字面量就是结构体的字面值,即指定结构体的值定义。未手动初始化的字段将会以其数据结构的零值初始化。
数组
数组(Array)是编程语言的一种基本的数据类型,是一定数量同类型数据的列表:
var arr1 [3]int
fmt.Println(arr1) // [0 0 0]
var arr2 [2]string
fmt.Println(arr2) // [ ]
arr3 := [6]int{1, 2, 3, 4, 5}
fmt.Println(arr3) // [1 2 3 4 5]
数组在内存中占用连续的空间,其大小必须在编译期就确定,因此不允许使用未指定长度的数组,但使用[...]可以让其在编译期根据内容自动推导长度:
var arr4 = [...]int{1, 2, 3}
fmt.Println(arr4) // [1 2 3]
可以使用数组下标对数组取值:
var arr4 = [...]int{1, 2, 3}
fmt.Println(arr4[1]) // 2
数组的长度实际上也是数组类型的一部分,因此不同长度的数组是完全不同的。
切片
切片(Slice)是一种可变大小的数据列表类型,它可以灵活的操作其内容,但它底层仍然是一个固定大小的数组。切片在实际使用中比数组更加常见。
切片的声明不需要指定其长度,如果指定了长度那就是数组:
var slice1 []int
fmt.Println(slice1) // []
var slice2 = []int{1, 2, 3}
fmt.Println(slice2) // [1 2 3]
var arr1 = [...]int{1, 2, 3}
fmt.Println(reflect.TypeOf(slice2)) // []int
fmt.Println(reflect.TypeOf(arr1)) // [3]int
切片提供了截取的方法,方便从中获取指定位置的值:
slice := []int{1, 2, 3, 4, 5, 6}
var s []int = slice[1:4]
fmt.Println(s) // [2 3 4]
截取的范围从左边的数值开始直到右边的数值(不包括),比如[1:3],就代表切片中下标从 1 到 2 的两个数。可以省略:左右的下标值,即默认为最小(最大)下标:
slice := []int{1, 2, 3, 4, 5, 6}
var s1 []int = slice[:4]
fmt.Println(s1) // [1 2 3 4]
var s2 []int = slice[2:]
fmt.Println(s1) // [3 4 5 6]
var s3 []int = slice[:]
fmt.Println(s3) // [1 2 3 4 5 6]
同样的,对数组也可以进行截取,但获得的是一个切片:
arr := [...]int{1, 2, 3, 4, 5, 6}
var s = arr[1:4]
fmt.Println(s) // [2 3 4]
fmt.Println(reflect.TypeOf(s)) // []int
对数组的引用
names := [4]string{"Angle", "Bob", "Cecelia", "Dog"}
fmt.Println(names) // [Angle Bob Cecelia Dog]
a := names[0:2] // [Angle Bob]
b := names[1:3] // [Bob Cecelia]
fmt.Println(a, b) // [Angle Bob] [Bob Cecelia]
b[0] = "???"
fmt.Println(a, b) // [Angle ???] [??? Cecelia]
fmt.Println(names) // [Angle ??? Cecelia Dog]
从上面这段代码可以看到,a和b都各自截取了names的一部分切片,当改变其中一个的内容时,另一个有共同元素的切片也会被改变,并且其底层引用的数组也发生了改变。这就说明了切片实际上是对数组的引用,它的底层仍然是数组,并且直接指向了原数组所在的存储空间。当以上代码中names为切片类型时其输出相同。
在 Golang 中,一个切片不存储任何数据,它只是描述了底层数组的一部分。也就是说,声明并初始化一个切片,它实际上操作的是一个数组,是对数组元素的全部截取。
切片字面量
一个切片的字面量就像没有长度的数组字面量,以下是数组字面量:
[3]bool{true, true, false}
切片字面量会创建一个相同的底层数组,然后创建一个引用它的切片:
[]bool{true, true, false}
可以定义一个结构体切片:
s := []struct {
name string
age int
}{
{"Dog", 12},
{"Pig", 13},
{"Cat", 15},
}
fmt.Println(s) // [{Dog 12} {Pig 13} {Cat 15}]
切片的长度和容量
切片包含两个属性:长度(length)和容量(capacity):
切片的长度表示的是切片中实际包含的元素个数
切片的容量表示的是切片底层数组的元素个数,从该切片中第一个元素开始计算
创建一个printSlice函数用于输出指定切片的 length 和 capacity 以及切片的内容:
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
s1 := s[:0]
s2 := s[:4]
s3 := s[2:]
printSlice(s) // len=6 cap=6 [2 3 5 7 11 13]
printSlice(s1) // len=0 cap=6 []
printSlice(s2) // len=4 cap=6 [2 3 5 7]
printSlice(s3) // len=4 cap=4 [5 7 11 13]
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
上述代码的四个切片底层共用一个数组,他们各自包含了起始元素的地址、切片长度和切片容量:
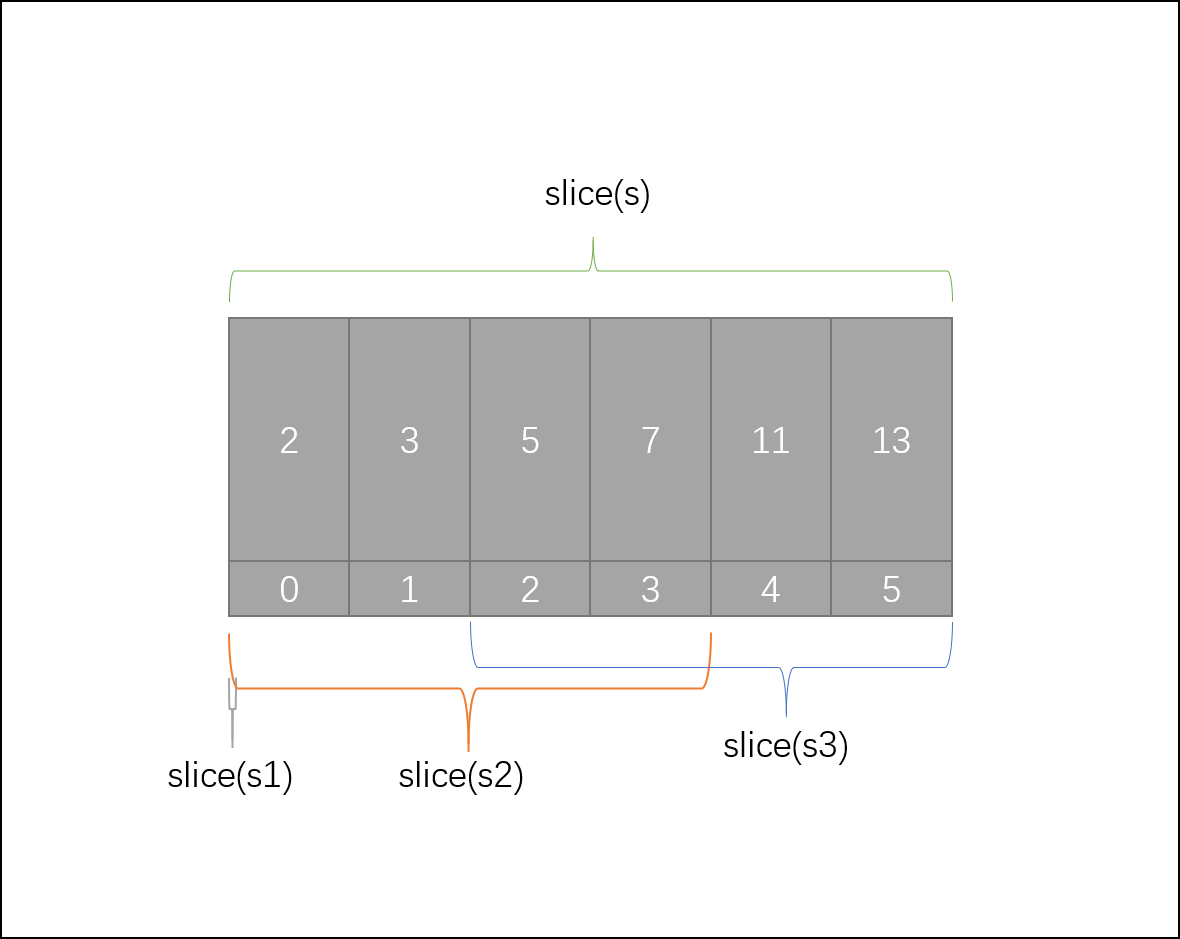
- 切片
s从数组的首位开始,长度和容量均等于数组的大小 - 切片
s1从数组的首位开始,长度为 0,但从首位开始计算数组的长度为 6,即切片的容量为 6 - 切片
s2从数组的首位开始,长度为 4,容量同上为 6 - 切片
s3从数组的第 2 位开始,长度为 4,从第二位计算数组的长度为 4,即切片容量为 4
切片的容量主要用于判断底层数组有没有足够的空间给切片延伸长度,当切片扩容但容量不足时,它会开辟新的内存空间将底层数组扩容:
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7}
printSlice(s) // len=4 cap=4 [2 3 5 7]
s = append(s, 1, 2, 2, 3) // 往切片里新增4个元素,填满底层数组
printSlice(s) // len=8 cap=8 [2 3 5 7 1 2 2 3]
s = append(s, 1) // 往切片里新增1个元素
printSlice(s) // len=9 cap=16 [2 3 5 7 1 2 2 3 1]
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
可以看到当切片扩容后长度大于其容量(底层数组大小)时,底层数组的大小会直接翻倍,也就是说,新数组的大小是原数组的两倍。数组在内存中是连续存储的,因此当连续的空间不足时,数组就无法在当前位置直接扩容。这时候,程序会寻找一个满足新数组大小的连续内存空间,将原数组全部拷贝过去来实现底层数组的扩容。
空切片
切片作为一种数据类型同样具有零值,它的零值是nil,其length和capacity的值均为 0:
var s []int
fmt.Println(s, len(s), cap(s)) // [] 0 0
if s == nil {
fmt.Println("nil") // nil
}
创建切片
Golang 提供了内建的make方法,可以用来创建一个切片:
s1 := make([]int, 5) // make([]Type, Len)
fmt.Println(s1, len(s1), cap(s1)) // [0 0 0 0 0] 5 5
s2 := make([]int, 5, 5) // make([]Type, Len, Cap)
fmt.Println(s2, len(s2), cap(s2)) // [0 0 0 0 0] 5 5
切片的切片
切片的元素可以是任意数据类型,其中就包括切片:
sliSli := [][]string{
[]string{"+", "-", "="},
[]string{"-", "+", "="},
[]string{"=", "+", "_"},
}
sliSli[0][0] = "?"
for i := 0; i < len(sliSli); i++ {
fmt.Println(sliSli[i])
}
// [? - =]
// [- + =]
// [= + _]
上述sliSli切片初始化语句还可以省略:
sliSli := [][]string{
{"+", "-", "="},
{"-", "+", "="},
{"=", "+", "_"},
}
切片的元素添加
很多时候都需要对切片元素进行添加,Golang 提供了内建的append函数来实现对切片的元素添加,在前面的“切片的长度和容量”一节中就曾使用过:
var s []int
fmt.Println(s) // []
s = append(s, 0)
fmt.Println(s) // [0]
s = append(s, 1, 2 ,3)
fmt.Println(s) // [0 1 2 3]
append 的第一个参数是原切片,其后一个或多个参数是需要添加的新元素,函数返回一个新的切片,他包含了原切片的所有元素和新元素。
当切片的底层数组大小不足时会分配一个更大的数组,返回的切片会指向这个新分配的数组。
遍历切片
内建函数range用于在for循环中遍历slice和map:
slice := []int{1, 2, 3 ,4, 5}
for i, v := range slice {
fmt.Printf("Index:%d Value:%d\n", i, v)
}
// Index:0 Value:1
// Index:1 Value:2
// Index:2 Value:3
// Index:3 Value:4
// Index:4 Value:5
对切片迭代时会返回两个值:当前元素的下标以及当前元素的值的拷贝。
由于 Golang 中元素声明后必须被使用,因此可以使用_忽略range返回的值:
slice := []int{1, 2, 3 ,4, 5}
for _, v := range slice {
fmt.Printf("Value:%d\n", v)
}
// Value:1
// Value:2
// Value:3
// Value:4
// Value:5
Map
map 是一种将键(Key)映射到值(Value)的数据类型:
var m map[string]int // declare
m = map[string]int{
"a": 1,
"b": 2,
}
fmt.Println(m)
map 的零值是nil,值为nil的 map 不可以添加 key:
var m map[string]int
m["a"] = 1
fmt.Println(m)
// panic: assignment to entry in nil map
创建 Map
Golang 提供了内建的make方法,可以用来创建一个 map:
m := make(map[string]int)
m["A"] = 1
m["B"] = 2
fmt.Println(m) // map[A:1 B:2]
使用make创建的 map 为空,但它的值不是nil:
var m1 map[string]int
var m2 = make(map[string]int)
fmt.Println(m1 == nil) // true
fmt.Println(m2 == nil) // false
Map 字面量
map 字面量类似于 struct 字面量,但必须要指定 Key:
type age int
var m = map[string]age{
"Dog": 12,
"Pig": 1,
"Cat": 13,
}
fmt.Println(m) // map[Cat:13 Dog:12 Pig:1]
可以省略结构体类型名:
type Person struct {
gender string
age int
}
var m1 = map[string]Person{
"Tom": {"MAN", 12},
"Autumn": {"WOMAN", 13},
}
var m2 = map[string]struct {
gender string
age int
}{
"Tom": {"MAN", 12},
"Autumn": {"WOMAN", 13},
}
fmt.Println(m1)
fmt.Println(m2)
Map 操作
插入一个键值对:
m[key] = value
获取一个键值对的值:
v := m[key]
删除一个键值对:
delete(m, key)
查询 map 中是否存在某个键值对:
type age uint8
m := make(map[string]age)
m["Jerry"] = 12
if value, ok := m["Tom"]; ok {
fmt.Println(value)
} else {
fmt.Println("NOTEXIST " + strconv.Itoa(int(value)))
}
if value, ok := m["Jerry"]; ok {
fmt.Println(value)
} else {
fmt.Println("NOTEXIST " + strconv.Itoa(int(value)))
}
// NOTEXIST 0
// 12
当键值对不存在时,map 返回值数据类型的零值。
遍历 map
使用内建函数range对 Map 进行遍历:
num := map[string]int{
"a": 1,
"b": 2,
"c": 3,
}
for k, v := range num {
fmt.Printf("Index:%q Value:%d\n", k, v)
}
// Index:"b" Value:2
// Index:"c" Value:3
// Index:"a" Value:1
多次执行可以发现,其遍历的结果并非有序,这其实是有意为之,强制要求程序不会依赖 Map 底层具体的哈希函数实现。
函数值
函数值(Function Values)同样是一种数据类型,和其他类型一样可以被使用:
func main() {
sum := calc(func(a, b int) int {
return a + b
})
fmt.Println(sum) // 3
}
func calc(fn func(a, b int) int) int {
result := fn(1, 2)
return result
}
上面的 main 函数调用了calc(),传入了一个用于计算和的匿名函数给,calc()又给传入的函数两个参数计算其和,最终由calc()返回。
函数闭包
闭包(Closure)指的是一个函数值,它从其外部引用变量,该函数可以访问外部变量并可以对外部变量进行赋值:
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 3; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
其中,adder()返回的就是一个闭包,上面的 main 函数内的代码基本等同于下面的代码:
func main() {
for i := 0; i < 3; i++ {
fmt.Println(
adder()(i),
adder()(-2*i),
)
}
}
方法和接口
方法
Golang 并没有一般面对对象语言中类的概念,不过支持对某一个类型定义方法。
方法(Method)指的是一个指定接收者(Receiver)的函数,也就是说方法属于于特定的类型。注意,方法只能作用于同一个包下面的类型。
下面是方法的用法:
type Person struct {
name string
age uint8
}
type Door bool
func (p Person) getName() string {
return p.name
}
func (d Door) getDoorStatus() bool {
return bool(d)
}
func main() {
p1 := Person{"Tom", 12}
p2 := Person{"Jerry", 11}
var d1 Door = false
fmt.Println(p1.getName())
fmt.Println(p2.getName())
fmt.Println(d1.getDoorStatus())
}
方法和普通的函数唯一的区别就是方法默认指定了第一个参数并把它放到了函数名前面,上面的getName方法就等同于下面的getName函数:
func getName(p Person) string {
return p.name
}
func main() {
p1 := Person{"Tom", 12}
fmt.Println(getName(p1))
}
指针接收者
不使用指针接收者的情况下,传入的只是变量的拷贝,并不会对变量本身进行修改,使用指针接收者能够传递变量指针直接修改变量值:
type person struct {
name string
age int
}
func (p person) SetName(name string) {
p.name = name
}
func (p *person) SetRealName(name string) {
p.name = name
}
func main() {
p := person{"Jack", 12}
p.SetName("Tom")
fmt.Println(p) // {Jack 12}
p.SetRealName("Tom")
fmt.Println(p) // {Tom 12}
}
上述的代码等同于:
type person struct {
name string
age int
}
func SetName(p person, name string) {
p.name = name
}
func SetRealName(p *person, name string) {
p.name = name
}
func main() {
p := person{"Jack", 12}
SetName(p, "Tom")
fmt.Println(p) // {Jack 12}
SetRealName(&p, "Tom")
fmt.Println(p) // {Tom 12}
}
可以注意到使用指针接收者的情况下,上述代码调用方法时使用的是p.SetRealName而非(&p).SetRealName,而在等价的函数中,必须传入变量p的地址。这是 Golang 提供的便利用法,在调用为指针接收者的方法时,会自动将p.SetRealName解释为(&p).SetRealName,因此二者是等价的。
函数和方法还有以下差别:
func (p person) setName(name string) {
p.name = name
}
func setName(p person, name string) {
p.name = name
}
func main() {
p := person{"Jack", 12}
p.setName("Tom")
fmt.Println(p) // {Jack 12}
(&p1).setName("Tom")
fmt.Println(p) // {Jack 12}
setName(p, "Tom")
fmt.Println(p) // {Jack 12}
setName(p, "Tom") // Compile error
fmt.Println(p)
}
可以注意到对于非指针接收者方法,仍然可以使用(&p)传入,然而对于不接受指针参数的函数使用指针,则不能通过编译。
使用指针接收者的目的主要有两个:
- 使该方法可以修改其接收者指向的值
- 避免在每个方法上复制被操作变量的值
第二点在大型项目中尤为重要,当某一个类型有大量的方法时,不使用指针接收者会导致调用每个方法都需要复制一份该类型的变量值。
嵌入结构体
通过嵌入匿名结构体的方式能够继承这些匿名结构体的方法,从而实现 OOP 的继承特性:
type Person struct {
Name string
Age int
}
type Student struct {
Person
Class string
}
func (p *Person) SetName(name string) {
p.Name = name
}
func (s *Student) SetClass(class string) {
s.Class = class
}
func main() {
s := &Student{}
s.SetName("John")
s.SetClass("class-1")
fmt.Println(s) // &{{John 0} class-1}
}
方法值&方法表达式
方法和函数一样能够作为值传递给变量或作为参数传递给函数/方法:
func main() {
p := &Person{}
setName := p.SetName
setName("John")
fmt.Println(p) // &{John 0}
}
使用类型而不是该类型的实例作为接收者,同样能够调用,比如使用*T:
func main() {
p := &Person{}
(*Person).SetName(p, "John")
fmt.Println(p) // &{John 0}
}
这被称为方法表达式。可以看到原本只能接收一个参数的SetName函数现在还可以接收一个其接收者类型的变量,也就是说当使用方法表达式时,接收者作为第一个参数传给方法,它现在和普通函数的用法相同了。
同样的,使用T:
func (p Person) SetName(name string) {
p.Name = name
}
func main() {
p := Person{}
Person.SetName(p, "John")
fmt.Println(p) // { 0}
}
使用非指针接收者的时候SetName修改的是p的拷贝,因此并没有修改p的字段值。
接口
接口(Interface)定义为一组方法的签名。
接口类型的值可以包含实现那些方法的任何值。
// Sender 接口
type Sender interface {
Send()
From()
}
type message struct {
msg string
from string
}
type mail struct {
msg string
from string
to string
}
func (m *message) Send() {
fmt.Println("已发送", m.msg)
}
func (m *message) From() {
fmt.Println("发送者", m.from)
}
func main() {
var s Sender
s = &message{
msg: "你好",
from: "Tom",
}
s.Send() // 已发送 你好
s.From() // 发送者 Tom
}
上述代码中定义了一个接口Sender,两个结构体message和mail,其中message有两个方法Send和From,因此message实现了Sender`接口。
接口可以接收实现它的类型的值,因此可以将&message{}赋值给接口变量s,这个变量可以操作其定义的所有方法。当有其他类型实现这个接口时也是同样的操作。
隐式实现
Golang 中接口的实现是隐式的,而不是某些语言中显式的实现(如 Java 中的inplements关键字),隐式实现能让定义的接口与其实现取消关联:
type I interface {
M()
}
type T struct {
S string
}
func (t T) M() {
fmt.Println(t.S)
}
func main() {
var i I = T{"hello"}
i.M()
}
可以看到上述代码中因为T有一个方法M而自动隐式实现了接口I,这其中并未有显式的声明。
接口的值
接口的值(interface values)可以看作一个值和该值具体类型的二元组,即(value, type),我们在关于接口的第一段代码中加入一行:
func main() {
var s Sender
s = &message{
msg: "你好",
from: "Tom",
}
s.Send()
s.From()
// 加入下面一行
fmt.Printf("%v %T", s, s) // &{你好 Tom} *main.message
}
可以看到输出了这个接口值的类型。也就是说,调用这个接口底下的方法就是调用其值的同名方法,即:
var s Sender
var m = message{
msg: "你好",
from: "Tom",
}
s = &m
// 下面两句代码的输出相同
s.Send() // 已发送 你好
m.Send() // 已发送 你好
内部值为 nil 的接口
当赋给接口变量的是一个为 nil 的具体类型的值时,接口的方法会调用为接收者是 nil 的方法:
type Sender interface {
Send()
}
type message struct {
msg string
}
func (m *message) Send() {
if m == nil {
fmt.Println("NIL")
return
}
}
func main() {
var s Sender
var m *message // nil
s = m
s.Send() // NIL
fmt.Printf("%v %T", s, s) // <nil> *main.message
}
在 Golang 中这样使用并不会报错。要注意的是,接口变量包含的值为 nil,但接口本身是非 nil 的值,比如其中还包含值类型。
值为 nil 的接口
前面一节说的是接口内存储的类型值为 nil 的情况,而这一节就说的是接口本身为 nil 的情况:
func main() {
var s Sender
s.Send()
}
// panic: runtime error: invalid memory address or nil pointer dereference
上面的代码会报错,这是因为为 nil 的接口没有包含任何类型,也就没有办法去调用这些类型的方法。
空接口
空接口是一个很常用的东西,不包含任何方法签名的接口叫做空接口:
type i interface{}
空接口可以包含任何类型,因此它常用于处理未知类型的变量,我们可以从fmt.Println函数了解它的用法:
// Println formats using the default formats for its operands and writes to standard output.
// Spaces are always added between operands and a newline is appended.
// It returns the number of bytes written and any write error encountered.
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
可以看到标准库中的fmt.Println函数接收多个类型为interface{}的值,然后我们往下寻找程序代码中具体处理interface{}类型变量的代码:
// Some types can be done without reflection.
switch f := arg.(type) {
case bool:
p.fmtBool(f, verb)
case float32:
p.fmtFloat(float64(f), 32, verb)
case float64:
p.fmtFloat(f, 64, verb)
case complex64:
p.fmtComplex(complex128(f), 64, verb)
case complex128:
p.fmtComplex(f, 128, verb)
case int:
p.fmtInteger(uint64(f), signed, verb)
case int8:
p.fmtInteger(uint64(f), signed, verb)
case int16:
p.fmtInteger(uint64(f), signed, verb)
case int32:
p.fmtInteger(uint64(f), signed, verb)
case int64:
p.fmtInteger(uint64(f), signed, verb)
case uint:
p.fmtInteger(uint64(f), unsigned, verb)
case uint8:
p.fmtInteger(uint64(f), unsigned, verb)
case uint16:
p.fmtInteger(uint64(f), unsigned, verb)
case uint32:
p.fmtInteger(uint64(f), unsigned, verb)
case uint64:
p.fmtInteger(f, unsigned, verb)
case uintptr:
p.fmtInteger(uint64(f), unsigned, verb)
case string:
p.fmtString(f, verb)
case []byte:
p.fmtBytes(f, verb, "[]byte")
case reflect.Value:
// Handle extractable values with special methods
// since printValue does not handle them at depth 0.
if f.IsValid() && f.CanInterface() {
p.arg = f.Interface()
if p.handleMethods(verb) {
return
}
}
p.printValue(f, verb, 0)
default:
// If the type is not simple, it might have methods.
if !p.handleMethods(verb) {
// Need to use reflection, since the type had no
// interface methods that could be used for formatting.
p.printValue(reflect.ValueOf(f), verb, 0)
}
}
可以看到上述代码使用了复杂的switch语句来枚举每一种类型的情况,从而最终实现对不同类型的输出(这其中使用了类型断言,后面会讲到)。这样的写法是由于 Golang 中没有泛型导致的(在将来的版本更新中或许会加入)。
类型断言
类型断言(Type Assertions)用于获取接口内部值和值类型,当类型匹配时则无错误:
func main() {
var i interface{}
i = 12 // int
t := i.(int) // int 匹配 int
fmt.Println(t) // 12
}
当类型不匹配时程序直接报错:
var i interface{}
i = 12 // int
t := i.(string) // string 不匹配 int
fmt.Println(t)
// panic: interface conversion: interface {} is int, not string
类型断言只能应用于接口变量,不能用于其他类型变量:
var i int
i = 12 // int
t := i.(int)
fmt.Println(t)
// invalid type assertion: i.(int) (non-interface type int on left)
可以使用两个左值来进行类型判断,即便断言失败也不会引发panic:
t, ok := v.(T) // T 指代类型
当类型匹配时ok为true,否则为false,可以实现下面的代码:
func main() {
var iSlice = []interface{}{
"string",
12,
nil,
int64(12),
}
for _, v := range iSlice {
if t, ok := v.(string); ok {
fmt.Printf("true: %v %T\n", t, t)
}else{
fmt.Printf("false: %v %T\n", t, t)
}
}
}
// true: string string
// false: string
// false: string
// false: string
可以看到,当断言失败的时候,左值t的类型变为了断言类型T,其值变为了该类型的零值。
类型 Switch
在前面的空接口小节中有提到,fmt.Println()最终实现不同类型的处理使用的是类型断言,并且采用了switch语句进行区分,具体参考前面的代码。
Stringers
fmt包定义了一个Stringer接口,这是一个很特殊的接口:
type Stringer interface {
String() string
}
这个接口可以将其本身描述为一个字符串,很多包都使用了这个接口来输出值:
type Person struct {
name string
age int
}
func (p *Person) String() string {
return fmt.Sprintln(p.name, p.age)
}
func main() {
var p1 = &Person{"Tom", 12}
var p2 = &Person{"Jack", 11}
fmt.Printf("%v%v", p1, p2)
}
// Tom 12
// Jack 11
可以看到无需显式调用,String方法就自动被调用了,我们修改一下方法名:
type Person struct {
name string
age int
}
func (p *Person) Format() string {
return fmt.Sprintln(p.name, p.age)
}
func main() {
var p1 = &Person{"Tom", 12}
var p2 = &Person{"Jack", 11}
fmt.Printf("%v%v", p1, p2)
}
// &{Tom 12}&{Jack 11}
上述代码并没有调用Format方法。
错误处理
Golang 的错误处理非常的丑,至少我是这么认为的 ㄟ( ▔, ▔ )ㄏ。
内建的error接口用于保存错误:
type error interface {
Error() string
}
参考Stringers,fmt包也会去寻找error接口并调用它的Error方法:
type MyError struct {
When string
What string
}
func (e *MyError) Error() string {
return fmt.Sprintf("At %s, %s",
e.When, e.What)
}
func run() error {
return &MyError{
time.Now().Format("2006-01-02"),
"it didn't work",
}
}
func main() {
if err := run(); err != nil {
fmt.Println(err) // At 2021-04-23, it didn't work
}
}
Golang 中大量使用if err != nil这样的错误处理方式:
err := handleError() // return error type
if err != nil {
fmt.Println(err) // 输出错误
}
fmt.Println("没有错误")
Readers
标准库中的io包定义了一个接口io.Reader,它用于表示数据流的读取端。
Golang 标准库中有许多对这个接口的实现,包括文件处理、网络连接、压缩器、密码相关等等。
io.Reader接口有一个Read方法:
func (T) Read(b []byte) (n int, err error)
Read方法往传入的字节切片中填入数据,并返回填充的字节数和一个错误值,当它读到字节流的末端时会传回一个io.EOF错误。
参考示例代码:
func main() {
r := strings.NewReader("Hello, Reader!")
b := make([]byte, 8)
for {
n, err := r.Read(b)
fmt.Printf("n = %v err = %v b = %v\n", n, err, b)
fmt.Printf("b[:n] = %q\n", b[:n])
if err == io.EOF {
break
}
}
}
// n = 8 err = <nil> b = [72 101 108 108 111 44 32 82]
// b[:n] = "Hello, R"
// n = 6 err = <nil> b = [101 97 100 101 114 33 32 82]
// b[:n] = "eader!"
// n = 0 err = EOF b = [101 97 100 101 114 33 32 82]
// b[:n] = ""
上面的代码中,strings.NewReader方法生成了一个strings.Reader结构体,其内部字符串值为"Hello, Reader!",并将其赋值给变量r。另外有一个 8 字节长度的字节切片b。
for循环体中,Read方法读取r的内容将其写到b中,并传回写入的字节长度给n。并且,它每次读取r的值后都会记录读取结束的位置,当下一次调用时就会从上次结束的位置开始读取。
for循环每次循环都会重复以上步骤,但由于b的容量只有 8 字节,因此每次最多只能读入 8 个字节的内容给b。当读到r的数据末尾时,则返回io.EOF错误。
另外注意上面的代码,字节切片b在Read方法中被修改了值,这就是因为切片类型只是对底层数组的引用,虽然传入Read方法内的切片和b不同,但它们的底层数组相同,因此改其一另一个也会被改变。
并发
并发指的是多个任务在同一时间内一起执行,注意是同一时间内而不是同一时刻。并行是多个任务在同一时刻同时执行,这需要硬件上支持并行,而并发则是让多个任务在极短的时间内快速切换执行,从而达到伪并行的效果。
Goroutines
Goroutine 是由 Go runtime 管理的轻量级线程,使用go关键字创建:
func main() {
for i := 0; i < 10; i++ {
go run(i)
}
}
func run(i int) {
fmt.Print(i)
}
上面的程序没有返回任何信息,这是因为main函数同样也是一个 Goroutine,其中的循环创建了多个新的 Goroutine,但还没等这些 Goroutine 运行main函数就先运行结束了,因此整个程序都结束了。
为了避免上述情况,最简单的方法是使用time.Sleep函数让main函数等待其他 Goroutine 运行完:
func main() {
for i := 0; i < 10; i++ {
go run(i)
}
time.Sleep(2 * time.Second)
}
func run(i int) {
fmt.Print(i)
}
// 9183467502
输出的结果每次都是不一样的,这是因为这些 Goroutine 并发执行,其顺序完全由调度器决定,并不唯一确定。
Channels
Channels (中文一般称通道)是一种定义了类型的管道,可以往里面发送和接收值。
发送:
ch <- value // 将value的值发送到channel ch中
接收:
value := <- ch // 接收channel ch的值并为value初始化
数据按照箭头的方向流动,只有<-这一个操作符。
和 Map 以及切片一样,通道必须在使用前被创建:
ch := make(chan int) // channel of int
默认情况下,Channel 的发送和接收操作在其中一端未就绪时会被阻塞:
func main() {
ch := make(chan string)
go push(ch)
fmt.Println(<-ch) // 延迟输出了 abc
}
func push(ch chan string) {
time.Sleep(3 * time.Second)
ch <- "abc"
}
上面的程序中,push函数在三秒后往 Channel 内写入字符串abc,因此在这段时间内 Channel 的接收者一直处于阻塞状态直到 Channel 中有值。同样地,当接收者未就绪时发送者也会阻塞。
通过这个特性可以很好地对并发执行顺序进行管理,下面的代码就解决了前面并发执行输出结果顺序不定的问题:
func main() {
ch := make(chan int)
go add(ch)
for i := 0; i < 10; i++ {
fmt.Print(<-ch)
}
}
func add(ch chan int) {
for i := 0; i < 10; i++ {
ch <- i
}
}
// 0123456789
带缓冲区的 Channel
Channel 创建时默认是不带缓冲区的,也就是前面说的接收端和发送端必须都就绪的原因,然而可以选择创建带缓冲区的 Channel 在不同场景下解决某些问题:
func main() {
ch := make(chan int, 10)
go add(ch)
time.Sleep(3 * time.Second)
for i := 0; i < 10; i++ {
fmt.Print(<-ch)
}
}
func add(ch chan int) {
for i := 0; i < 10; i++ {
ch <- i
}
fmt.Println("Completed!")
}
// Completed!
// 0123456789
程序的输出中,后一行要晚出现几秒,这时候 Channel 内已经有 10 个元素了。再看一下不带缓冲区的 Channel:
func main() {
ch := make(chan int)
go add(ch)
time.Sleep(3 * time.Second)
for i := 0; i < 10; i++ {
fmt.Print(<-ch)
}
}
func add(ch chan int) {
for i := 0; i < 10; i++ {
ch <- i
}
fmt.Println("Completed!")
}
// 0123456789Completed! 或 0123456789
不带缓冲区的 Channel 发送和接收必须同时进行,因此add函数只能等待main函数休眠结束接收数据。而当最后一次循环结束后,main函数立即退出,如果在此之前fmt.Println("Completed!")没能执行的话,程序的输出结果就不包含*Completed!*了。
这里有一个地方要注意,并发执行的程序当缓冲区装满时,接收者会先将其中的元素全部接收,然后再对其进行发送操作,直到全部数据元素操作完毕。
在顺序执行的单个 Goroutine 中,往满 Channel 里写入元素会直接报错:
func main() {
ch := make(chan int) // 等同于make(chan int, 0)
ch <- 1
fmt.Println(<-ch)
}
// fatal error: all goroutines are asleep - deadlock!
Channel 的关闭
发送者可以使用close函数关闭一个 Channel 来表示这个 Channel 不再有值被传入,接收者也可以知道 Channel 是否关闭:
func main() {
ch := make(chan int, 10)
go push(ch)
for i := 0; i < 10; i++ {
if v, ok := <-ch; ok {
fmt.Print(v)
}
}
}
func push(ch chan int) {
for i := 0; i < 10; i++ {
if i == 5 {
close(ch)
break
}
ch <- i
}
}
// 01234
注意,只有发送者可以关闭 Channel,对已被关闭的 Channel 进行发送操作会引发panic,但对关闭的 Channel 进行接收不会,接收已关闭的 Channel 只会得到类型零值:
func main() {
ch := make(chan int)
go push(ch)
for i := 0; i < 10; i++ {
fmt.Print(<-ch)
}
}
func push(ch chan int) {
for i := 0; i < 10; i++ {
if i == 5 {
close(ch)
break
}
ch <- i
}
}
// 0123400000
Close 操作用于告知接收者无值可传,是非必须的操作,与 I/O 操作中的 Close 释放资源并不相似。
Channel 的 range 操作
for i := range ch语句能够接收 Channel 中的值直到 Channel 被关闭:
func main() {
ch := make(chan int, 10)
go push(ch)
for i := range ch {
fmt.Print(i)
}
}
// 01234
Select
select语句可以让一个 Goroutine 等待多个通信操作:
func main() {
ch := make(chan int)
signal := make(chan int)
go input(ch, signal)
for {
select {
case v := <-ch:
fmt.Printf("%d ", v)
case <-signal:
fmt.Print("Done")
return
}
}
}
func input(ch, sig chan int) {
for i := 0; i < 10; i++ {
ch <- i
if i == 5 {
sig <- 0
break
}
}
}
// 0 1 2 3 4 5 Done
可以设置default关键字用于设置无接收时的输出:
func main() {
tick := time.Tick(100 * time.Millisecond)
boom := time.After(500 * time.Millisecond)
for {
select {
case <-tick:
fmt.Print("tick")
case <-boom:
fmt.Print("BOOM!")
return
default:
fmt.Print(".")
time.Sleep(50 * time.Millisecond)
}
}
}
// ..tick..tick.tick..tick..BOOM!
TODO
- 变量作用域
- 斐波那契闭包
- Readers 练习
- Images
- 等价二叉树练习